在職修課期間有幾位網友問我會不會針對2.x的部份再寫些新的東西,當初真的是心有餘而力不足,現在其實也還是,因為我在玩天堂w...
不過如何總算是開始動手了,除了重寫所用到的extension之外,題目的部份也暫定是天堂w的血盟分鑽管理,如果這個題目走不下去的話就會調整成自己寫一個記帳網頁。
會選擇血盟分鑽的題目是因為,有在玩的就知道,每一筆交易都需要手續費,過於頻繁的交易會付出過多的手續費。如果可以月結的話,那也許無形成也可以省下一筆不少的費用,因為角色之間可以互相沖帳。
當然如果真的不行的話變成是一個記帳網頁也不錯,生活中很多開銷如果可以好好記錄,回頭可以看到不少亮點。雖然現在也已經有很多的手機app可以使用,而且有更好的服務,但是寫一個專屬於自己的工具那種感覺是很不錯的。
最重要的當然就是我們可以從實作中瞭解到Flask帶給我們的便利性,然後從一個lib延伸學習到更多的lib。舉例來說,flask就單純的是flask,你想要跟資料庫對接也許就會考慮使用flask-sqlalchemy,使用flask-sqlalchemy也許你會採用orm,那你就學到orm於sqlalchemy的整合應用。
總之,還是那句話,flask是自由的,自由的意思就是很多事情你要自己處理,而不是由flask這個框架幫你決定一切。
PS: 目前已重置完成flask-sqlalchemy、flask-login
YOLOv3實作整理
tags:
YOLOv3YOLODeepLearning相關模型可參考在下的github
YOLOv3,現在都已經v8了,我可能才剛整理好v3,因為我個人習慣上是盡可能的希望可以自己硬寫一發,神經網路可能是黑盒子無法解釋,但是方法本身如果是可解釋的我就盡可能的去瞭解,不過還是有一些小細節沒有很完整,但至少我有信心看完我寫的資料之後你也可以絕大部份的掌握YOLOv3,這對你再往後延伸閱讀很有幫助。
物體偵測的資料格式與一般分類任務的標記有很大的不同,也因此我們在實作之前一定要先能夠處理資料的轉變。舉例來說,如果是分類任務的話,那一張照片也許就是一個類別,但如果是物體偵測的話,那也許一張照片上面就有四五個物體標記資訊了。
也因此,我們就先需要做些資料處理的前置動作,這部份你可以參考Arch_YOLO_dataset_preprocess_1.ipynb以及Arch_YOLO_dataset_preprocess_2_data_for_yolov3.ipynb
這兩份文件主要在說明資料的前置處理,以及產生模型中計算loss所需要的資料格式。
整理好訓練資料之後就可以開始著手處理模型,我們知道,YOLOv3採用Darknet-53做為骨幹,這意謂著它有53層,骨幹的意思就是最主要的模型架構,但這是骨幹,YOLOv3的輸出跟Darknet-53是不一樣的,一個是做為物體偵測,一個是做為分類任務。
下圖給出YOLOv3的完整架構:
可以看的出來主要是將不同大小的feature map做結合,讓大小資訊可以結合在一起做為輸出預測,這樣子不同尺寸的ancbor box就可以有比較豐富的資訊。
針對Darknet與YOLOv3的模型說明可以參考Arch_YOLOv3_1_Darknet-53_structure.ipynb與Arch_YOLOv3_2_YOLOv3_structure.ipynb的說明。這兩篇文章中對於架構的部份有著較為詳細的說明,可以更直觀的瞭解到模型中特徵圖(feature map)的變化。
接下來要處理的就是loss function,自己手寫過一次就會有一種,『啊,原來還可以這樣處理』的感覺出現。如下圖所示:

loss function的部份大致分為三個部份:
詳細的細節可以參考Arch_YOLOv3_3_loss_function。框的好不好可以用IoU來判斷,有沒有信心跟框到什麼就是用cross_entropy,這很標準。不過或許是因為我沒有先用影像分類的任務來做預訓練,訓練起來有點不順利,也因此loss function的部份我在實作上是有做些許調整的。
在Arch_YOLOv3_3_loss_function裡面有一個函數,decoder,這主要是拿來調整模型得到的feature map,整個資料流大致如下:
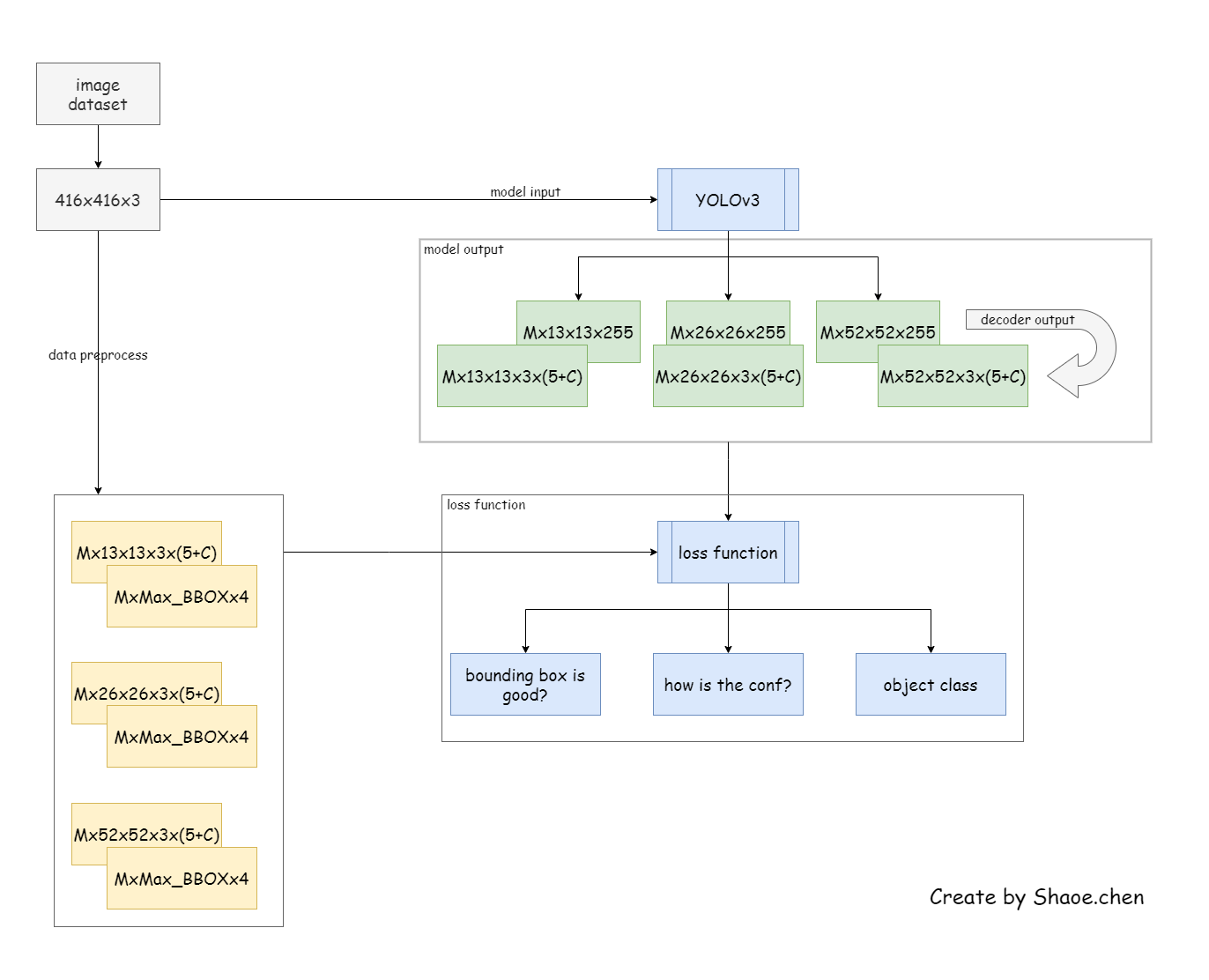
現在我們已經可以進入訓練的步驟了,有一些說不上來的細節,像是AP50之類的計算我還沒有實作上,所以目前來看是沒有這一個數值可以提供參考的,唯一有的就是loss。正如上面提到的,或許是因為我沒有先做預訓練,所以訓練過程中常常會造成梯度的消失或是爆炸等問題。也因此整個訓練過程真的很長,常常早上看的時候發現loss又nan,我把我的訓練過程通通寫在Arch_YOLOv3_4_training,算是幫自己做個過程中記錄:

訓練之後我們需要做個推論測試,所以拿了張照片就看看它的原始狀態,再用我們訓練完成的模型看看推論出來的狀態,這可以參考Arch_YOLOv3_5_predict。得到的推論結果如下:
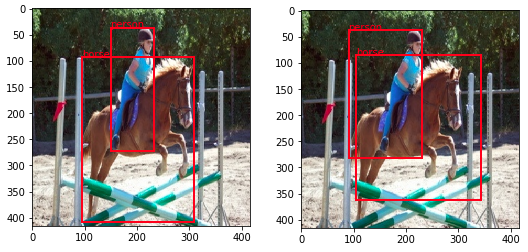
上圖左是原始框的資料,然後上圖右是訓練後模型推論得到的資料,結果看似不錯,不過中間還是存在置信度的問題就是了,或許還需要更次的迭代。
以上就差不多是整個模型的處理過程了,前陣子已經看到發表YOLOv8了,我的v4才正要開始動手,有點慢,不過相信有這個基礎在可以很快速的推進才是。